What Is Robots TXT File? How It Works in SEO
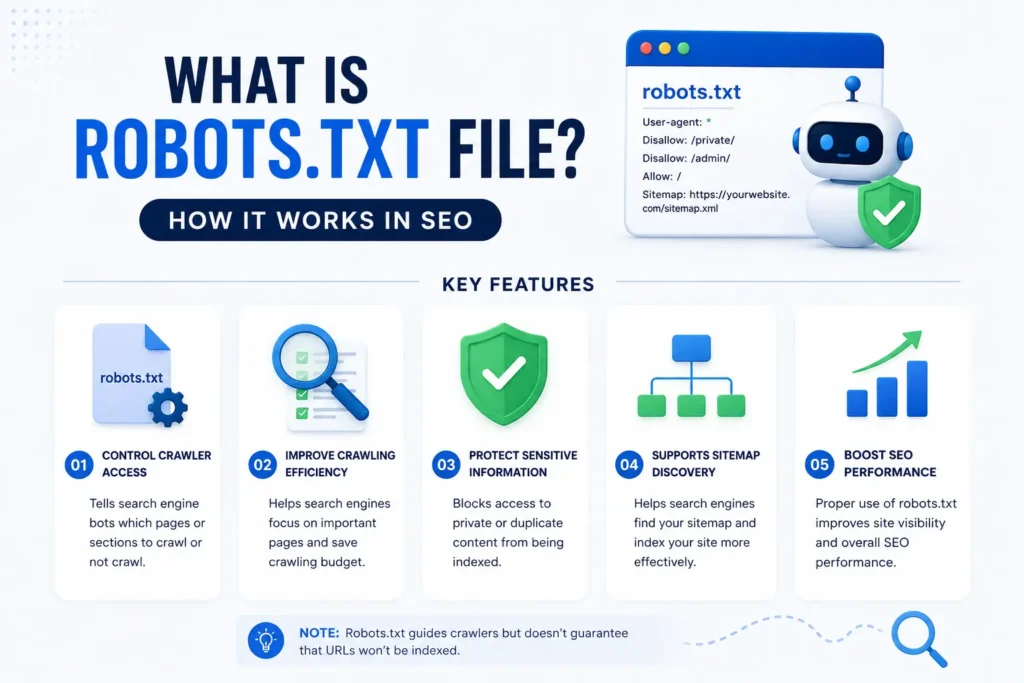
कई बार ऐसा होता है कि आपने website पर नया page publish किया, लेकिन Google Search में वह दिखाई ही नहीं देता। दूसरी तरफ कुछ ऐसे pages, जिन्हें आप search results में नहीं दिखाना चाहते, वे crawl होने लगते हैं। अगर आपने कभी Google Search Console use किया है या technical SEO के बारे में पढ़ा है, तो आपने robots.txt file का नाम जरूर सुना होगा। लेकिन beginners के मन में अक्सर सवाल होता है What Is robots txt file और यह SEO में इतनी important क्यों मानी जाती है? आसान भाषा में समझें तो robots.txt file website का एक instruction file होती है, जो search engine crawlers को बताती है कि website के कौन से हिस्से crawl करने हैं और किन्हें avoid करना है। यह website owner और search engines के बीच communication bridge की तरह काम करती है। जब मैंने पहली बार एक WordPress website की crawl report check की थी, तब समझ आया कि कई unnecessary pages Google crawl कर रहा था, जिससे important content की visibility प्रभावित हो रही थी। सही robots.txt setup के बाद crawling pattern बेहतर दिखा। लेकिन इसकी सही understanding जरूरी है, क्योंकि एक छोटी गलती indexing को प्रभावित कर सकती है। सबसे interesting बात यह है कि robots.txt file SEO में helpful होने के साथ risky भी साबित हो सकती है। Robots txt file का मतलब एक ऐसी text file से है जो search engine crawlers को website crawl करने के rules बताती है। यह file decide करती है कि Googlebot किन pages को access कर सकता है और किन्हें avoid करना चाहिए। सही robots.txt setup website crawling को बेहतर organize कर सकता है। What Is Robots TXT File और SEO में इसकी क्या भूमिका है? Robots txt file का सबसे सीधा जवाब यह है कि यह website की crawling instructions file होती है। यह search engines को guide करती है कि website के कौन से sections crawl करने हैं और किन्हें skip करना है। Robots.txt file एक ऐसी text-based file है जो website के root directory में रखी जाती है। इसका purpose website crawling control करना होता है। आसान शब्दों में, यह file Googlebot और दूसरे bots को instructions देती है कि कौन से pages access किए जा सकते हैं। robots txt file in seo इसलिए महत्वपूर्ण मानी जाती है क्योंकि यह crawl budget optimization में मदद कर सकती है। अगर भारतीय उदाहरण लें, तो imagine कीजिए कि आप किसी बड़े office building में security guard हैं। हर visitor को हर room में जाने की permission नहीं होती। कुछ areas public होते हैं और कुछ restricted। Robots.txt file भी website के लिए ऐसा ही permission gate बनाती है। जब मैंने पहली बार एक eCommerce website audit की, तब देखा कि filter URLs और duplicate parameter pages unnecessary crawl हो रहे थे। Robots.txt optimization के बाद crawl efficiency improve हुई। हालांकि यह समझना जरूरी है कि robots.txt file हर case में same SEO impact नहीं देती क्योंकि website structure भी equally important होता है। Industry experts के अनुसार, सही crawl management website efficiency improve करने में मदद कर सकता है। Robots TXT File in SEO कैसे काम करती है? Robots txt file in seo search engines को instructions देकर crawling behavior manage करती है। इसका मुख्य काम bots को access permissions देना या रोकना होता है। जब कोई search engine crawlers जैसे Googlebot आपकी website पर आते हैं, तो वे सबसे पहले robots.txt file check करते हैं। यह file उन्हें बताती है कि website के कौन से paths open हैं और किन directories को avoid करना है। Allow और Disallow in Robots TXT कैसे काम करता है? allow and disallow in robots txt website crawling rules define करने के लिए use होते हैं। Allow command search engines को किसी page या directory access करने देती है, जबकि Disallow command access block करने का काम करती है। उदाहरण के लिए: Disallow: /admin/ इसका मतलब है कि search engines admin section crawl न करें। अगर इसे Indian railway analogy से समझें, तो कुछ train compartments सभी passengers के लिए open होते हैं, जबकि कुछ reserved होते हैं। Robots.txt file भी यही logic follow करती है कुछ website areas accessible रहते हैं और कुछ restricted। लेकिन एक nuanced point समझना जरूरी है। Robots.txt file किसी page को Google index होने से हमेशा नहीं रोकती। अगर किसी blocked page के external backlinks हों, तो वह limited form में दिखाई दे सकता है। इसलिए सिर्फ robots.txt को privacy tool समझना गलत होगा। Research studies ने दिखाया है कि crawl optimization large websites में performance indirectly improve कर सकती है। What Is robots.txt file और website indexing पर इसका प्रभाव Robots.txt file समझने के साथ यह जानना भी जरूरी है कि इसका website indexing पर क्या असर पड़ता है। Robots.txt crawling control करता है, लेकिन indexing control करने का इसका role limited होता है। Website indexing एक ऐसी process है जिसमें Google website pages को अपने database में store करता है ताकि search results में दिखाया जा सके। Robots.txt crawling को affect करता है, लेकिन हर blocked page indexing से automatically हट जाए यह जरूरी नहीं है। Robots TXT और Meta Noindex में क्या फर्क है? कई beginners robots.txt और noindex tag को एक जैसा समझते हैं, जबकि दोनों अलग concepts हैं। Robots.txt crawling restrict करता है Meta Noindex indexing रोकने के लिए use होता है अगर analogy से समझें, तो robots.txt किसी library के locked room जैसा है जहाँ visitors को जाने से रोका जाता है। दूसरी तरफ noindex ऐसा label है जो librarian को कहता है कि इस book को catalog में मत जोड़ो। जब मैंने एक client website troubleshoot की, तब उन्होंने accidentally important blog folder block कर दिया था। Result यह हुआ कि नए posts crawl ही नहीं हो रहे थे। Fix करने के बाद indexing धीरे-धीरे normal हुई। इससे यह समझ आया कि छोटी robots.txt mistake SEO visibility पर बड़ा असर डाल सकती है। सबसे important बात, robots.txt file SEO support tool है complete indexing control system नहीं। Robots TXT in WordPress कैसे setup करें? अगर आपकी site WordPress पर है, तो

